


35个
多项发明专利,35个软件著作权。

SmartUQ
不确定性量化工程分析软件
Quantify every uncertainty
 产品定义
产品定义
SmartUQ是第一款专门设计用于执行行业规模不确定性量化(UQ)和概率设计的商业工具。SmartUQ是一家财富100强喷气发动机制造商自始至终开发出来的,旨在解决UQ挑战,因为他们以前的工具无法处理问题的复杂性、规模和高维度。
后来,成功地将SmartUQ扩展为通用分析和机器学习工具,能够解决整个行业的难题。SmartUQ已广泛应用于汽车、航空航天和国防、涡轮机械、重型设备、医疗设备、半导体、能源以及石油和天然气等行业。SmartUQ软件帮助我们的《财富》500强客户解决了一些工程领域最困难的分析问题,为他们节省了数百万美元和数千小时的工作时间。
SmartUQ团队由世界一流的统计、工程和商业专家领导,形成了以目标为导向、以研究为基础的文化。我们自豪地为客户的不确定性量化、预测分析和机器学习需求创造了改变游戏规则的解决方案,而这些都不存在现成的解决方案。
▪ DOE 通常用于从系统中收集新数据。在许多情况下,已经收集到足够的数据。通常在这些场景中,收集到的数据是经过长时间积累的,并且有足够的数据进行分析。
例如,来自现场组件上的传感器的健康监测数据可以在组件的整个使用寿命期间连续捕获实时数据。SmartUQ 的数据采样工具可以划分数据以模拟由完整数据集的子集组成的空间填充 DOE。
与在数据收集之前开发的 DOE 不同,像二次采样和切片采样这样的数据采样采用现有的输入-输出数据对并选择能够很好地代表设计空间的点。
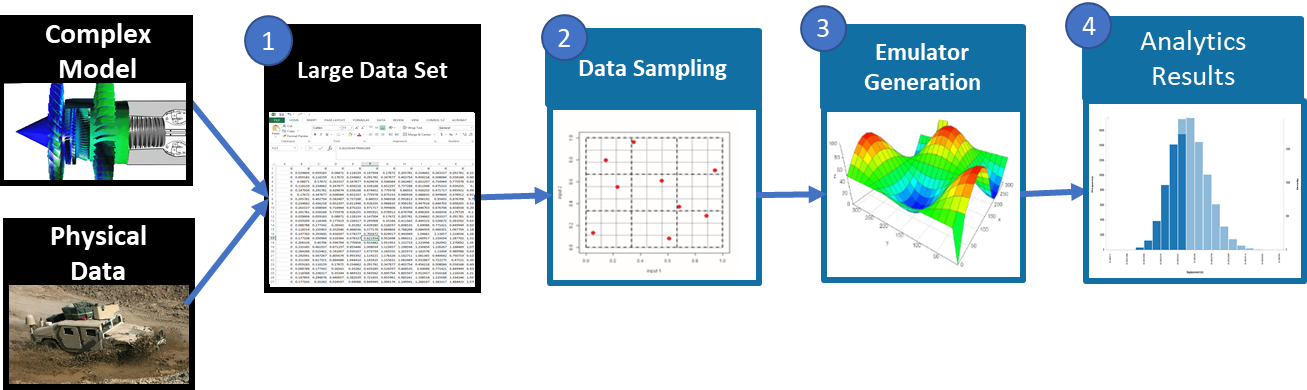
数据采样工作
流程数据采样工具的工作流程从从模拟和/或物理数据中收集的数据集开始。数据集往往很大,使用整个数据集进行分析可能对计算要求很高。SmartUQ 数据采样工具可以将数据集划分为能够很好地代表设计空间的较小子集。
▪ 二次采样算法:从现有的大型数据集中对用户指定数量的点进行抽样,以充分代表原始数据集。与任意将数据集一分为二不同,二次抽样工具会考虑模拟空间填充 DOE 的点,从而减少二次抽样数据集中的潜在偏差。
通过仅使用初始数据的子集,计算负担显着减少,同时通过智能选择过程保持准确执行高级分析的能力。较大的剩余数据子集可用于执行模型验证,从而节省模拟和测试资源,同时保持对预测准确性的信心。
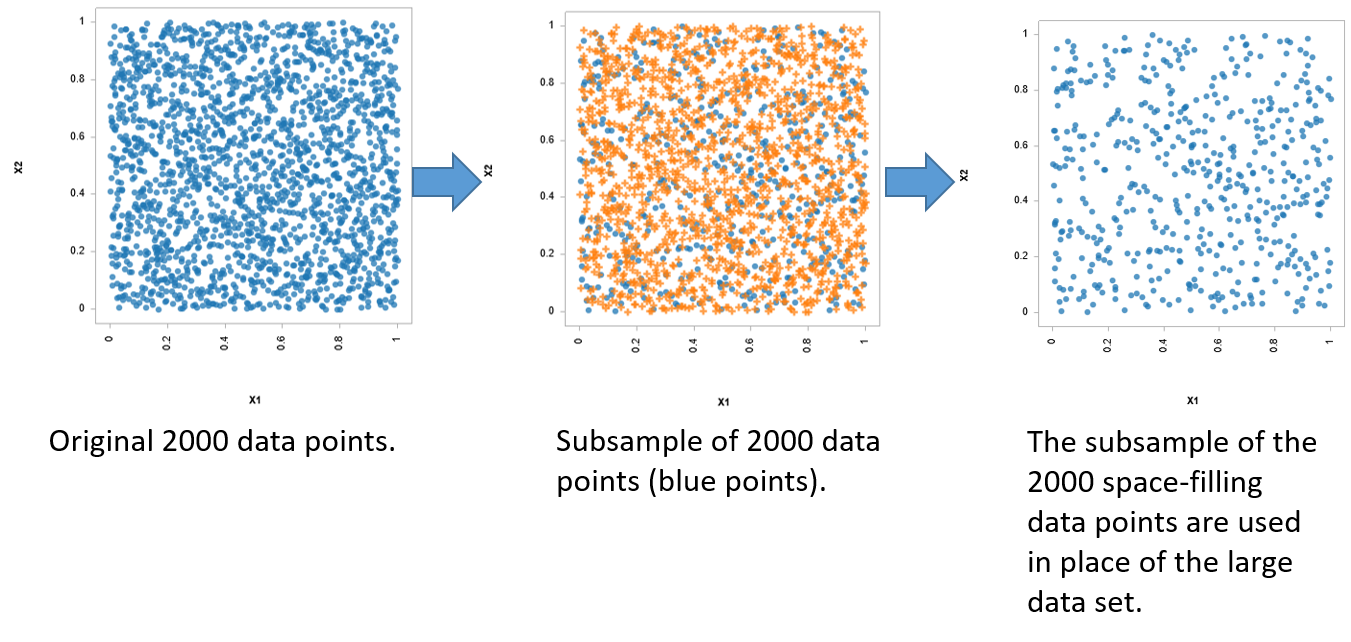
子采样过程
对子样本所在的现有数据集进行子采样模拟空间填充 DOE。
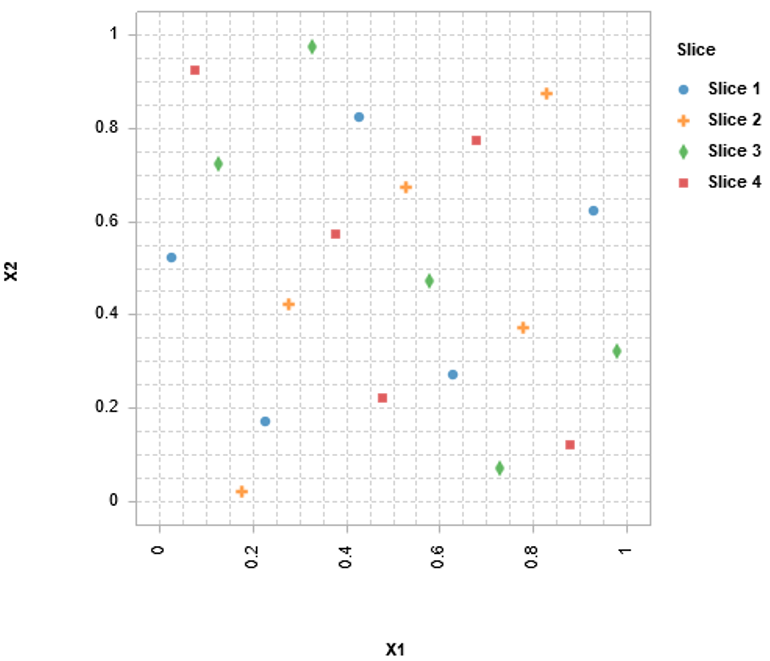
▪ 切片采样算法 与切片设计一样,切片采样算法将数据集分为几组。但是,不再假定初始数据集是空间填充设计。每个切片可用于构建模拟器或执行模型验证。切片结构启用的独特仿真过程是仿真的分而治之方法。
用于训练的每个切片都有自己的模拟器,然后将所有模拟器组合成一个模拟器以获得最终结果。这允许并行计算并减少执行大型数据集的高级分析所需的内存需求。
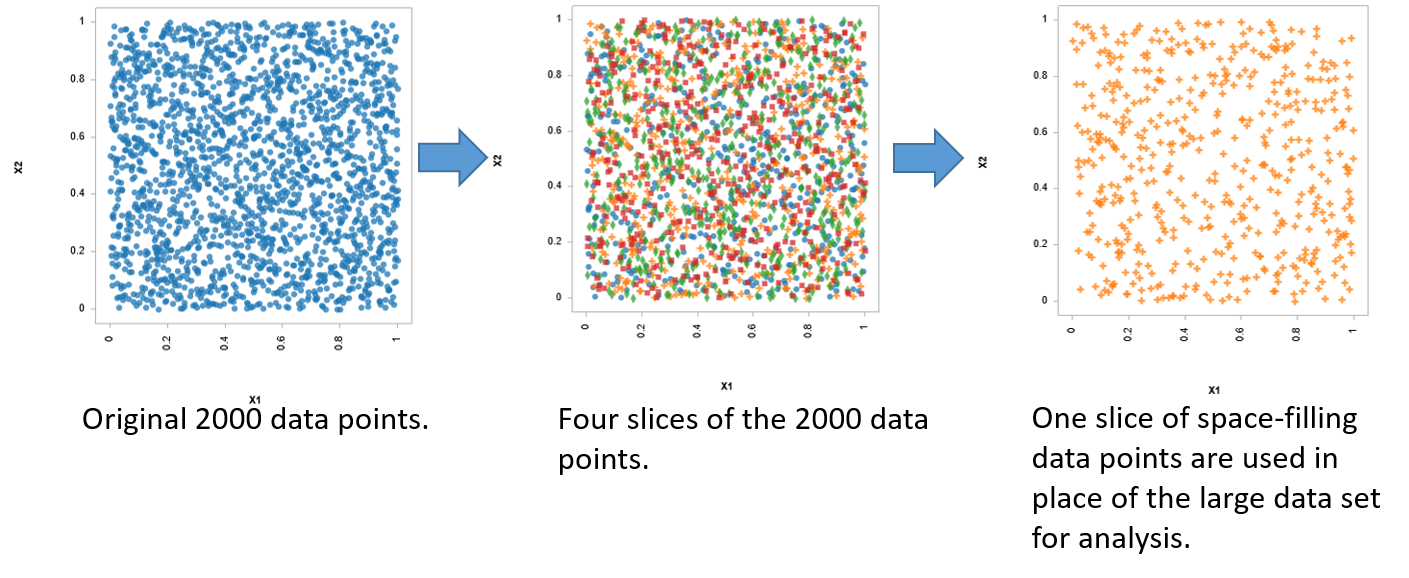
切片采样过程
将现有数据集切片为四个切片,其中每个切片模拟一个填充空间的 DOE。
▪ SmartUQ 提供了一套专门的空间填充设计、各种最先进的实验设计 (DOE) 和几个独特的正在申请专利的 DOE,以应对复杂的挑战。我们了解您在进行实验设计时有两个主要顾虑:获取足够的数据以准确表示正在采样的系统,以及通过减少样本数量来控制成本。
我们最先进的 DOE 可确保足够的采样,同时减少所需的点数。我们专有的 DOE 更进一步,使用来自先前采样点的信息来确定下一个样本应该在哪里采集,从而为您提供前进所需的数据。您甚至可以通过从大型观测数据集中进行二次抽样来跳出框框思考。此外,SmartUQ 灵活的 DOE 生成工具可让您根据特定需求定制采样。
当您选择 SmartUQ 软件来设计 DOE 时,您将获得更准确、更全面的结果,运行次数显着减少,从而节省了时间和金钱。
实验设计 (DOE) 是系统抽样模式,用于进行实验以确定输入和输出之间的因果关系。如果没有确保从正确的实验中收集到足够信息的 DOE,则可能很难或不可能达到测试的目标。如果您使用依赖于实验者或模拟用户的直觉的采样模式进行模拟或测试实验,则可能会导致对输入之间的交互方式缺乏了解,这可能会浪费测试资源并导致错失机会。
使用多个因素同时变化的多因素设计有助于解决这些问题。不仅要评估单个因素的影响,还要评估各种因素对或因素组合如何相互作用以改变输出值,这一点至关重要。
阶乘 DOE 提供了强大的信息收集能力,但它们通常需要以更大的成本采集更多样本,而不是在高度非线性系统中确定因果关系真正需要的样本。现代空间填充设计通常是具有高度非线性响应的模拟和复杂物理实验最有效的 DOE。
空间填充设计,例如拉丁超立方体设计和最优拉丁超立方体设计,对一系列均匀分布的代表性输入配置进行采样以填充设计空间。研究表明,这种类型的 DOE 最大限度地减少了运行次数,同时最大限度地提高了从每次模拟中获得的潜在学习。因此,空间填充设计提供了高精度,同时减少了采样点的总数。
顺序 DOE 使用多个 DOE,每个 DOE 都经过优化以填补先前采样模式中的空白。可以重复此过程以提高仿真器精度,通过仅运行实现所需精度水平所需的仿真来帮助最大限度地减少总仿真时间。
该 DOE 还允许结合多保真模拟的新选项。低保真仿真可用于生成仿真器并快速探索设计空间。为确保准确性,可以使用较小的高保真模拟样本来校准仿真器。当计算资源可用时,也可以使用此 DOE 战略性地运行模拟并提高仿真器的准确性。
例子
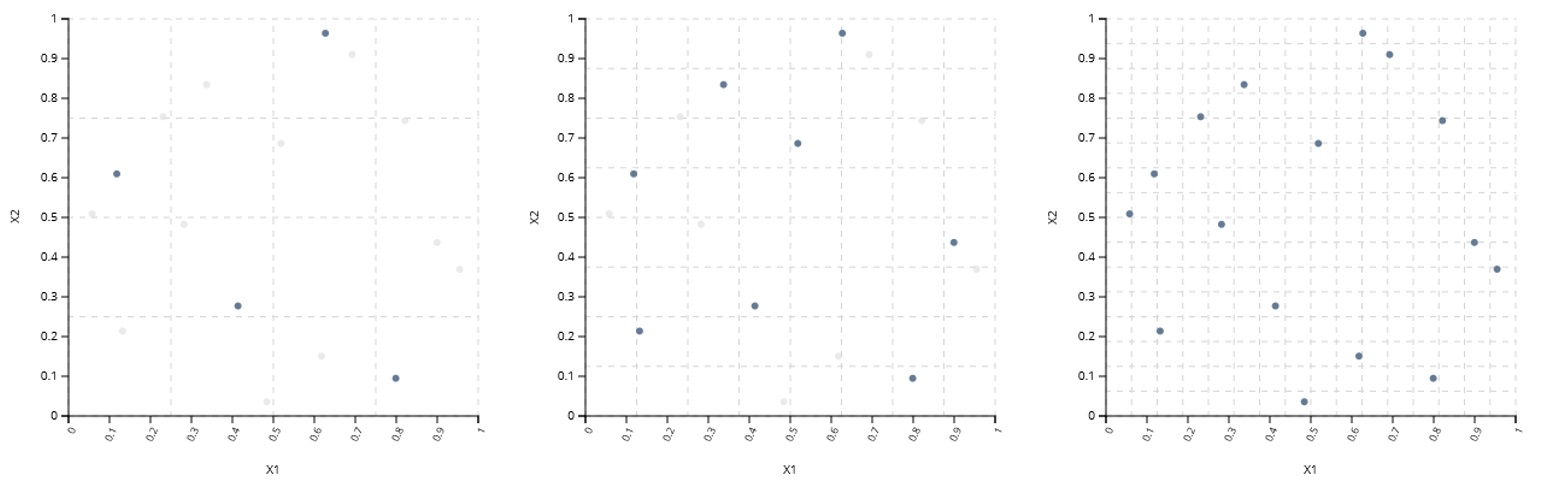
在并行 DOE 中,采样点被分成单独的并行批次。这在改变连续和离散输入的混合时特别有用:每个批次可以处理单独级别的离散输入。也可以通过构建每个批次来支持多个离散输入,使其由较小的并行 DOE 组成。
这些 DOE 还可用于在多个组之间划分计算和实验工作。对于计算机实验,能够在更大的计算设备组之间分配完整实验的计算负载可以显着减少时钟时间。
例子
并行 DOE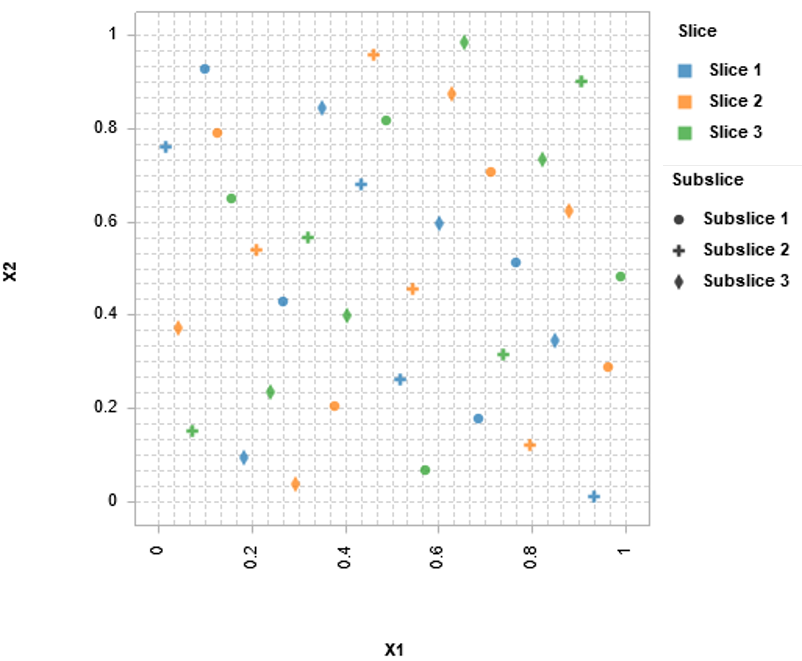
自适应设计允许用户通过自适应地向用于创建仿真器的 DOE 添加更多点来提高拟合仿真器(代理模型、元模型)的准确性。在这个过程中,仿真器是从现有的 DOE 和相关的结果数据中创建的。然后,该仿真器用于确定应在何处添加下一次仿真运行,以提高仿真器的准确性。可以重复此过程,直到达到所需的拟合精度水平。
例子 我们的算法使用两种方法模拟了此处显示的具有几个难以拟合的特征的测试表面:一次性优化拉丁超立方体设计和我们的自适应 DOE。
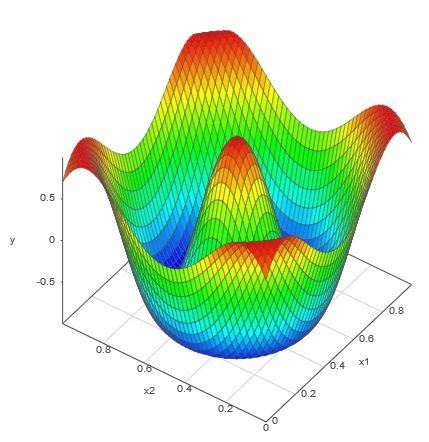 测试面
测试面第一个 DOE 是一次性最优拉丁超立方体设计。使用此 DOE 生成的仿真器产生了如下所示的模型表面。
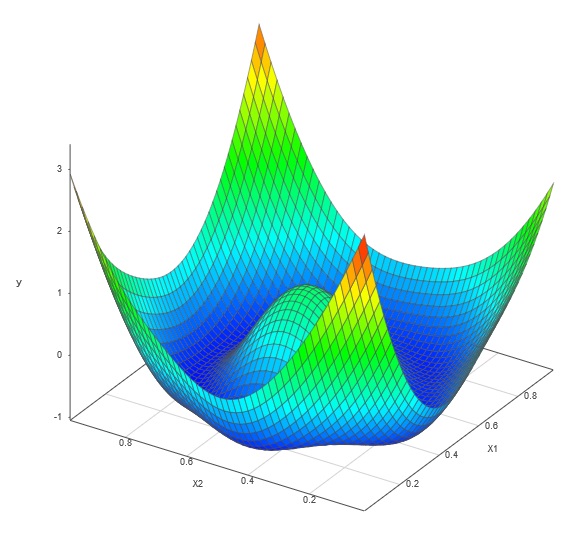 一次性优化 LHD
一次性优化 LHD
第二个 DOE 是我们专有的自适应 DOE。从最初的 20 点优化 LHD 开始,SmartUQ 的自适应设计功能在设计空间中一一增加了五个点。每个点都针对我们的算法基于先前仿真器选择的设计空间的特定区域。这种方法产生了一个更准确的模型,在使用相同数量的模拟运行时将误差减少了一个数量级。
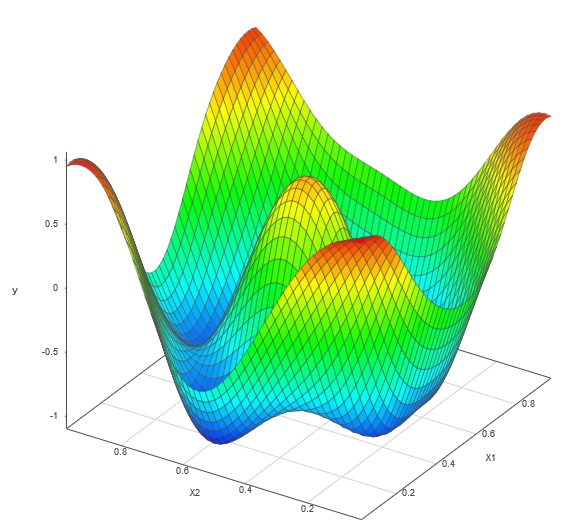 自适应 DOE
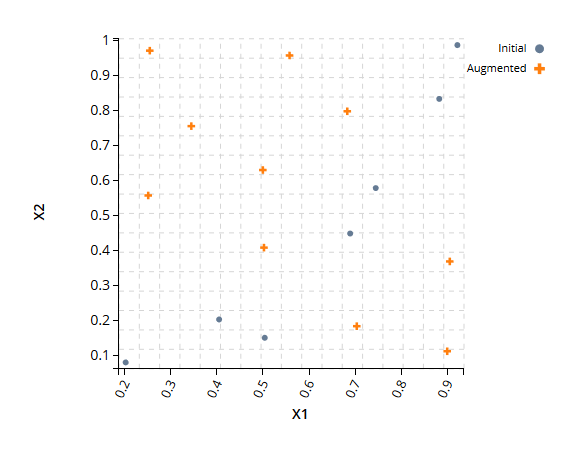
自适应 DOE设计增强允许用户生成与现有 DOE 相结合的 DOE,从而使新点最大化组合 DOE 的空间填充特性。在实践中,有时在一个模拟系列中运行大型 DOE 所需的所有设计点是不可取的或不可行的。
从以前的设计空间探索、优化程序和以前的产品开发周期中得到现有的 DOE 是很常见的。这些 DOE 可能没有良好的空间填充特性,但仍包含有价值的信息。设计增强可用于确定最大化从给定数量的新模拟运行中可以学习的信息所需的最佳模拟运行,同时还可以利用先前收集的数据。
设计增强与自适应设计不同:在设计增强中,仅根据现有 DOE 本身的属性生成最佳点。因此,新点对模拟结果是盲目的。在自适应设计中,最佳点是基于使用先前仿真结果创建的仿真器以及 DOE 的属性生成的。
设计增强比自适应设计更稳健,因为前者是无模型的,并且适用于具有任意数量响应的模拟。设计增强和自适应设计都是有用的补充工具,用户应根据正在研究的特定案例的属性在这两个选项之间做出决定。
例子
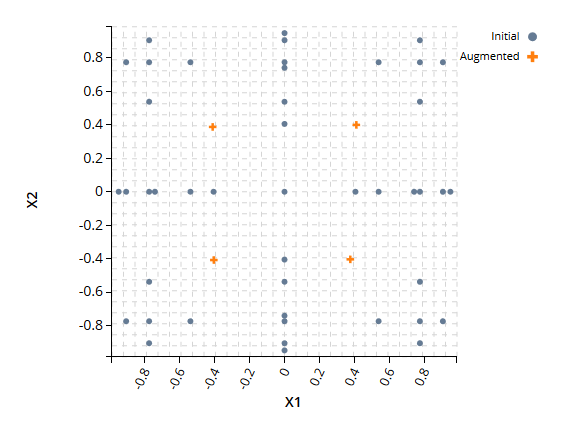
DOE 通常用于从系统中收集新数据。在许多情况下,已经收集到足够的数据。通常在这些场景中,收集到的数据是经过长时间积累的,并且有足够的数据进行分析。
例如,来自现场组件上的传感器的健康监测数据可以在组件的整个使用寿命期间连续捕获实时数据。SmartUQ 的数据采样工具可以划分数据以模拟由完整数据集的子集组成的空间填充 DOE。
与在数据收集之前开发的 DOE 不同,数据采样(例如二次采样和切片采样)采用现有的输入-输出数据对并选择能够很好地代表设计空间的点。
统计仿真被广泛用于预测和理解复杂系统的行为,例如在工程模拟和测试中发现的那些。仿真器快速预测系统响应的能力可用于各种密集分析,例如校准、灵敏度分析和不确定性传播。
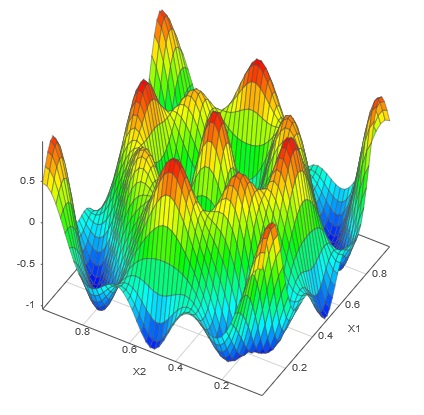
SmartUQ 突破性的仿真算法消除了使仿真器适应大数据集和高维系统的障碍,为使用不确定性量化和分析开辟了新的可能性。我们正在申请专利的技术可以轻松处理连续和离散输入,并且可以构建具有单变量、多变量、瞬态和函数输出的轻量级仿真器。它以闪电般的速度完成这一切。
SmartUQ 拥有针对大数据和多维数据集的改变游戏规则的仿真技术。我们准确的仿真技术可以快速绘制出复杂系统的整个输入到输出空间。我们可以在标准笔记本电脑上在几秒钟内安装一个 1,000 点的模拟器,在几分钟内安装一个 4,000 点的模拟器。使用以前的方法为相同的数据集构建模拟器可能需要数小时甚至数天。
例子
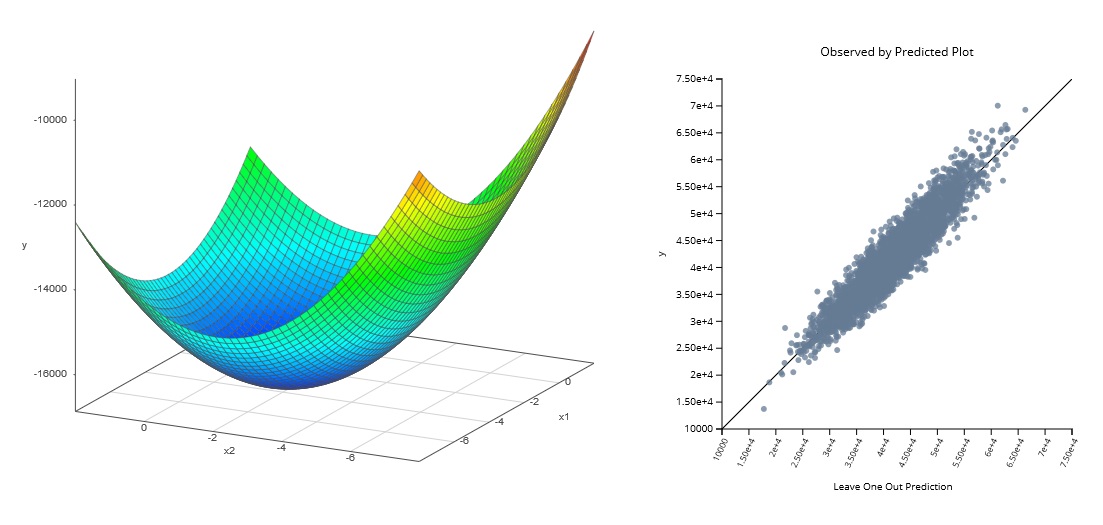
多变量响应仿真器对于具有多个连续输入和多个输出的系统(例如汽车模拟和测试)非常有效。提高效率意味着用户可以同时而不是单独探索和理解不同输出和输入之间的关系,从而使整个过程比以往更快。
例子:此处显示的仿真器是为适应具有 10 个输入变量和 3 个输出变量的 750 点数据集而构建的。SmartUQ 用不到 8 秒的时间在一台典型的笔记本电脑上构建了这个模拟器。
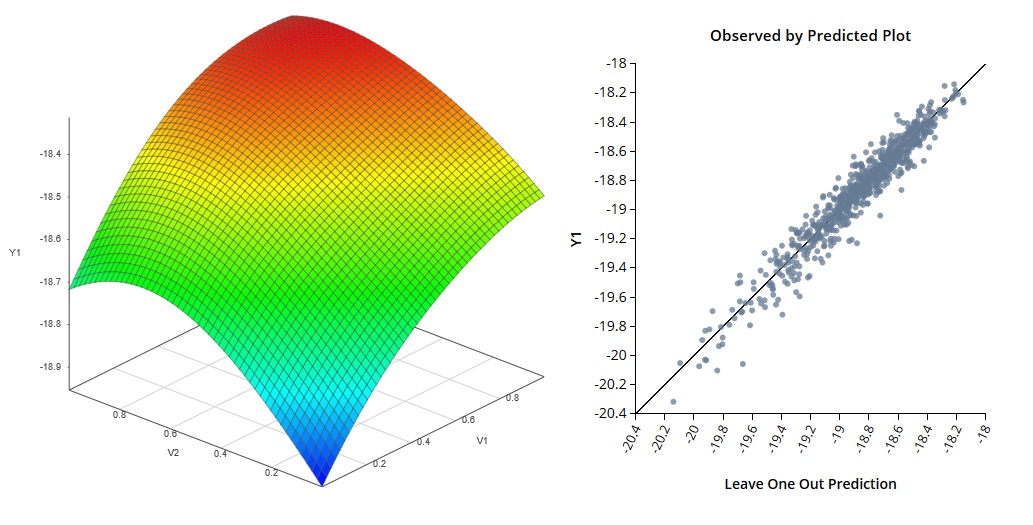
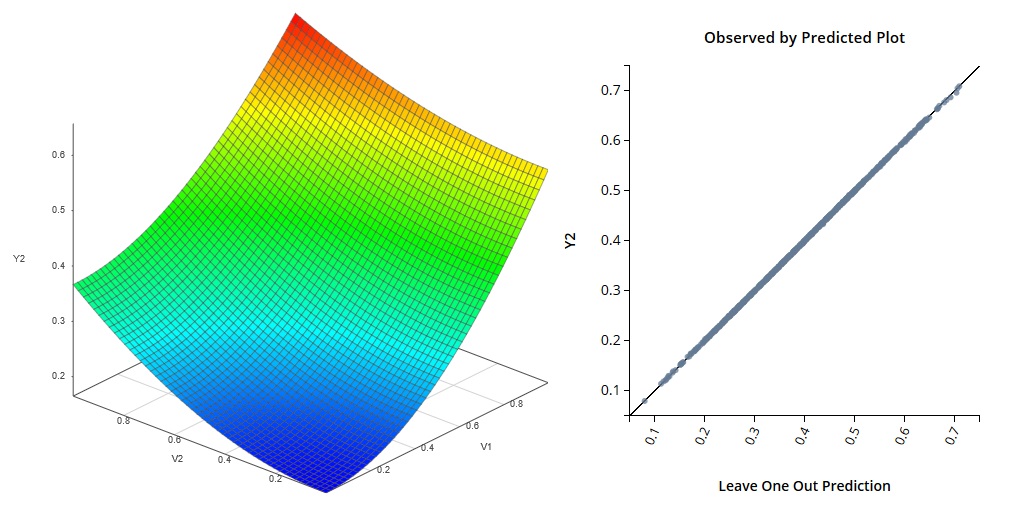
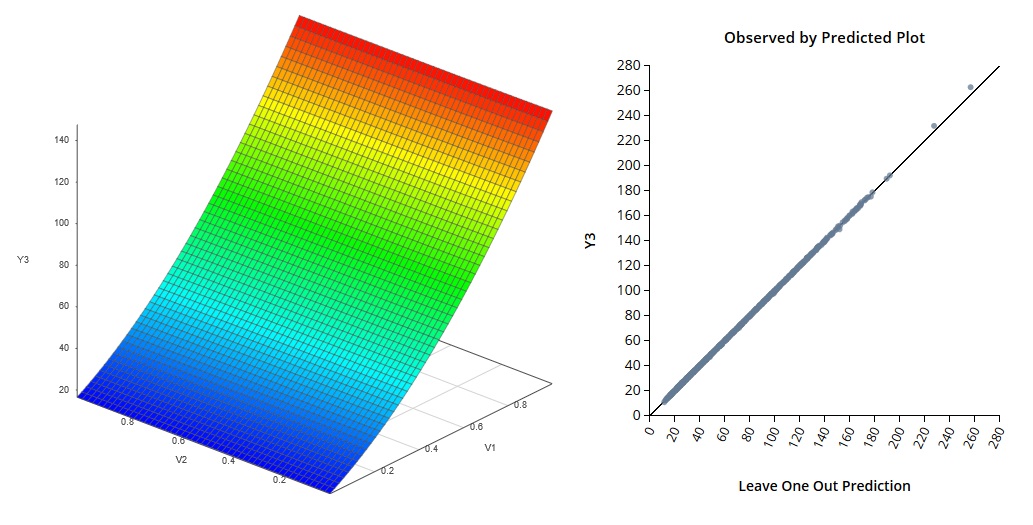 多元响应仿真示例 3
多元响应仿真示例 3当您处理具有连续和离散输入的系统时,混合输入仿真器非常有用。离散输入可以包括一组固定组件,甚至包括完全不同类型的设备或子系统的模拟。使用混合输入仿真意味着您可以轻松地为不同的设计构建仿真器并对其进行分析。通过一次考虑更多选项,您可以创建更好的设计。
飞机发动机模拟中离散变量的示例可能包括使用多个不同的求解器、涡轮叶片的多个离散尺寸和几何形状,或多种不同类型的涡轮/压缩机传动装置。
混合输入问题的一个例子是辐射泄漏模型,它可能涉及连续输入,例如水流速,以及离散输入,例如放射源材料的类型(例如,受污染的设备、燃料棒、玻璃化乏燃料)。
例子:此示例是使用具有六个连续输入和一个具有五个级别的离散输入的单变量响应混合输入仿真器创建的。SmartUQ 用不到 9 秒的时间从典型笔记本电脑上的 500 点数据集构建了一个模拟器。
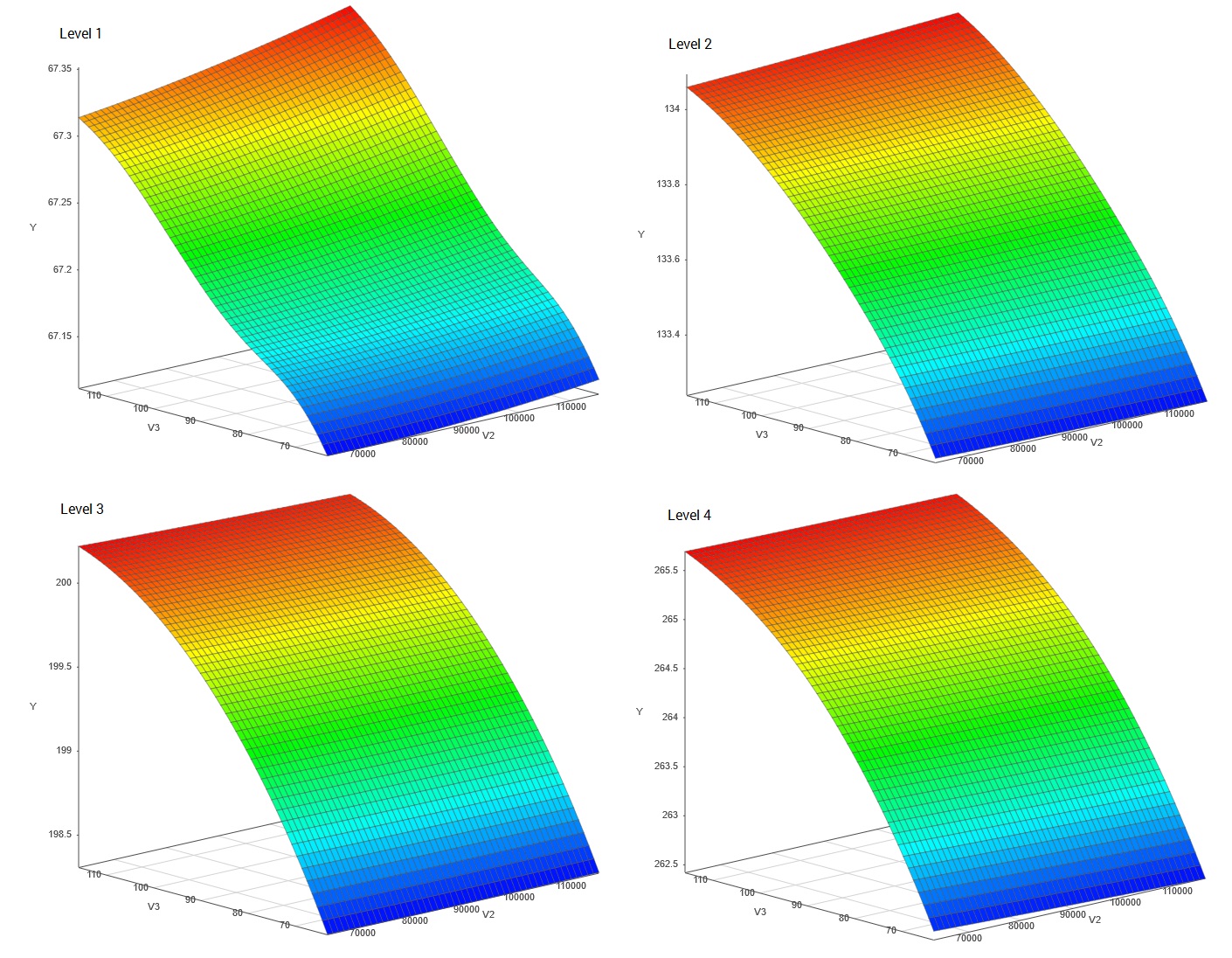
具有功能或瞬态输出的仿真用于所有工程领域。功能响应仿真器包括至少一个功能输入变量,例如时间或距离。对于每次模拟运行,输出具有与功能输入的一组值相对应的值。
一个例子是计算表面阻力的翼型模拟。该模拟可能有两个功能输入变量,时间和沿翼片长度的距离,以及一些非功能变量,例如平均空速、表面涂层类型和翼片横截面几何参数。每次模拟都使用一组非功能变量运行:例如,每次模拟只有一种表面涂层类型和几何形状。输出,表面阻力,在每个时间步长和沿翼片长度的每个位置计算,每个模拟结果是输出变量相对于功能输入变量的函数。因此,每组输入的表面涂层和几何结构都与机翼长度和模拟时间段内的阻力结果相关联。
SmartUQ 有一个单独的功能仿真器类,以利用输入和输出变量的功能映射,从而使仿真器的构建和使用更加高效。与其他输入变量相比,功能输入值(例如时间步长或位置)通常多几个数量级,这允许 SmartUQ 模拟更大的功能数据集。
例子
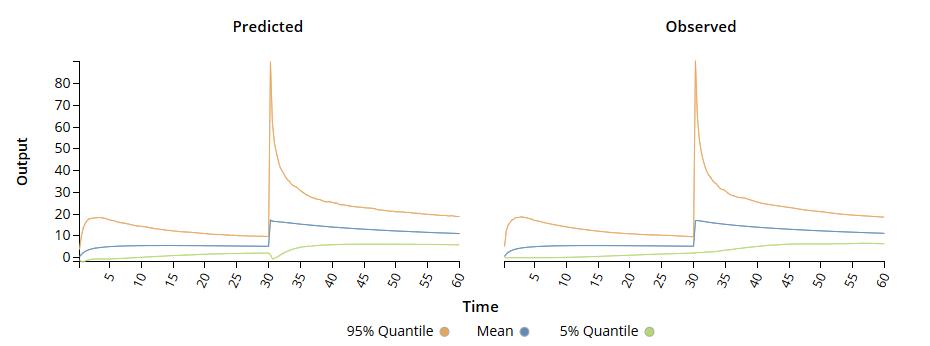 瞬态响应仿真器配置文件比较
瞬态响应仿真器配置文件比较▪ 统计校准概述 使用模拟代替物理测试对于加速分析和降低研究和设计成本已变得至关重要。然而,模拟结果可能与现实不同,使用统计校准和模型验证来充分利用接地模型中的有限测试数据至关重要。通过确保模拟尽可能接近现实来减少设计周期时间和节省成本的潜力从未如此巨大。
统计校准是调整模型校准参数以使模型与一组实验结果更好地吻合的过程。如果没有适当的校准,模型的结果可能毫无意义,甚至会提供有关其现实世界对应物的错误信息。
因此,准确的模型校准被广泛认为是建立具有足够可靠性的仿真模型的关键步骤,并且通常需要在进行任何进一步的研究或分析之前校准模型。
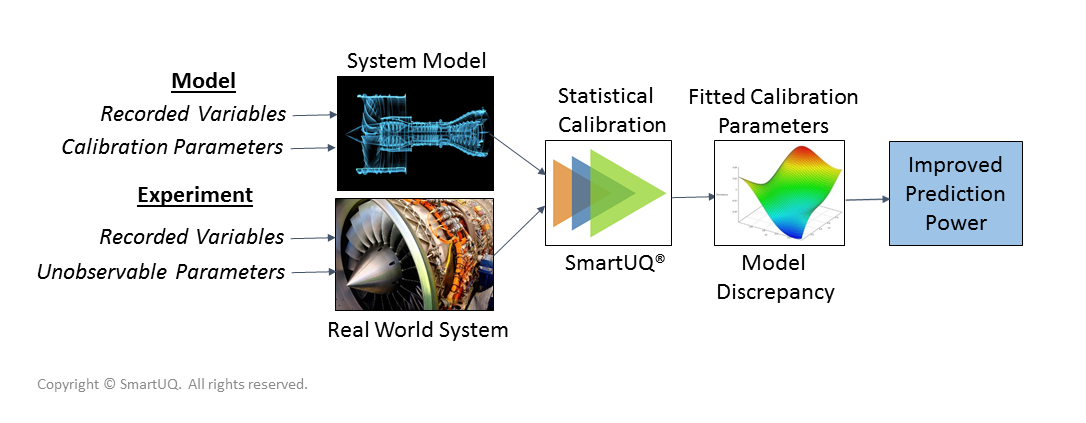 图 1:统计校准工作流程
图 1:统计校准工作流程统计校准的工作流程如上图所示。校准参数通常不是在物理测试中直接测量的。这些参数可能是难以测量的物理属性,例如材料和土壤属性、制造尺寸和发动机工作点,也可能是模型的完全非物理属性。
在卫星建筑物等系统的热模型中,通常需要校准各种输入参数,例如材料特性、组件的热容量、制冷剂特性、对流传热系数以及设备或系统性能。匹配的输出可以包括温度、能耗、热膨胀、加热速率、舒适度和设备故障预测。有这么多可能性,很容易理解为什么需要一个简单、易于使用、有效的校准工具。
最新一代的仿真工具包括高度详细的物理、更高的复杂性和更多的参数。物理测试也产生了越来越复杂的数据集。详细的仪器遥测很常见,处理它已成为大数据分析的问题。模拟和测试结果之间的差异是不确定性量化分析的重要组成部分,这些趋势向更复杂的模型和大型物理测试数据集发展,为不确定性量化和统计校准带来了新的挑战和机遇。
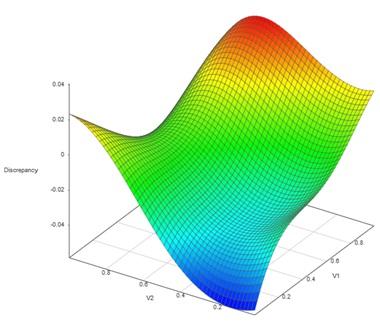
图 2:校准后的仿真模型与一组物理数据之间的差异预测的曲面图
统计校准有几个重要的优点。该方法允许模型所有方面的不确定性,包括拟合校准参数的不确定性。统计校准还确定了模型与优化校准参数的观测数据之间的差异。确定模型差异对于突出模型中的不足之处以及模型验证所必需的非常有用。左图显示了模拟和物理数据集之间模型差异的二维曲面图。
SmartUQ 的统计校准功能可以快速准确地调整模型。我们易于使用的界面允许您校准几乎任何模型,包括具有单变量或多变量输出的低维和高维模型以及高维输入。SmartUQ 强大的算法同时确定物理数据和模拟数据之间的差异,并准确计算校准参数。更好的是,校准模型所需的所有模拟运行都可以并行运行,从而大大减少了时钟时间。
统计校准的准确性与所使用的物理和模拟数据集有关。SmartUQ 提供了许多设计实验生成工具,旨在最大限度地提高统计校准的有效性和准确性。这些工具可以创建优化的组合物理和模拟实验设计,或帮助放置与现有数据集相关的物理和模拟实验。
敏感性分析量化了模拟模型输出相对于模拟输入变化的变化。使用从敏感性分析中获得的信息可以帮助确定哪些输入最相关,哪些可能被忽略。了解哪些输入很重要有助于及早突出潜在问题,改进模型以更准确或更有效,并缩小设计和优化中使用的搜索空间。考虑较少的因素可以大大减少必要的样本数量,从而降低成本并节省时间。这些能力使灵敏度分析在处理复杂系统和创建强大的解决方案时变得至关重要。
SmartUQ 具有两种经过验证的灵敏度分析解决方案:基于仿真和广义多项式混沌扩展 (gPCE)。
敏感性指数的一个简单例子是直线的斜率。斜率是 y 对 x 的敏感度的量度。确定更复杂的功能、实验和模拟的灵敏度通常要困难得多。输入通常具有交互效果,其中一个输入的变化会改变另一个输入的灵敏度,并且解开这些交互可能是一项复杂的任务。
SmartUQ 提供主效应灵敏度指数和总效应灵敏度指数。主效应指数衡量单个输入变量对输出的影响,但不考虑变量与其他输入变量的交互作用。总效应指数衡量一个输入变量的影响,同时考虑该变量与其他输入变量的相互作用。在研究非加法系统时,了解总效应指数至关重要。统一使用这两个指标可以在整个参数空间中提供更广泛的灵敏度度量。
由于采样密集型方法的速度提高,基于仿真器的灵敏度分析已成为一种流行的解决方案,特别是对于大样本量、非线性行为和高维度的问题。现在,通过使用 SmartUQ 的突破性技术,基于仿真器的灵敏度分析可以应用于比以往任何时候都大得多的问题。SmartUQ 中易于使用的灵敏度分析工具采用先前构建的仿真器,并为所有输入快速提供主效应和总效应指数。
例子
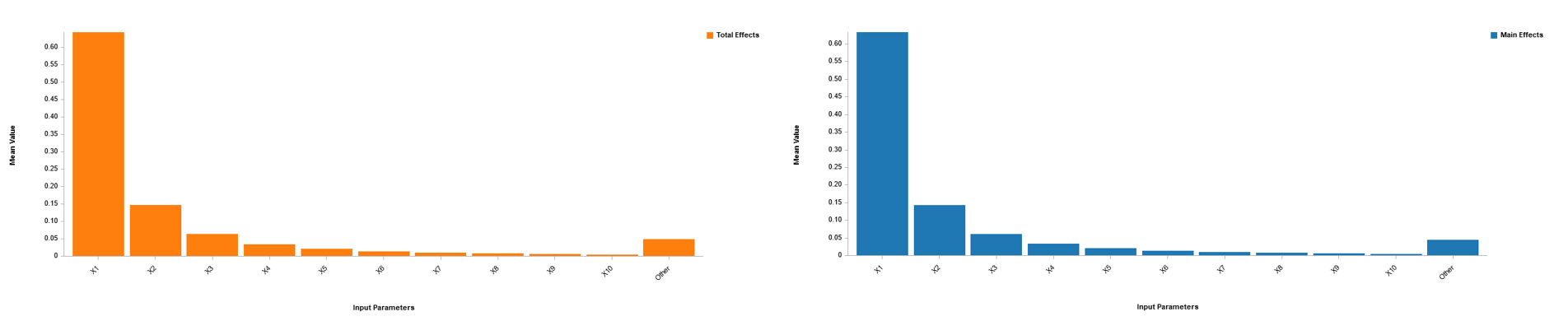
基于仿真器的敏感性分析
在本例中,构建了一个仿真器并用于对由 75 个输入变量、一个输出变量和 10,000 个点组成的数据集执行敏感性分析。主效应和总效应总结在上面的条形图中。
SmartUQ 具有易于使用的广义多项式混沌扩展 (gPCE) 工具。gPCE 是一种应用数学技术,用于使用一系列多元多项式来估计系统的行为。使用稀疏网格 DOE 对要评估的系统进行采样,然后使用 gPCE 来近似随机输出与其每个随机输入之间的函数关联。然后使用该近似值来计算不确定性传播和灵敏度分析结果。gPCE 在稀疏网格 DOE 所需的点数少和结果计算速度方面都是一种高效技术。
对于输出 Y,gPCE 可以写成一系列多元多项式。多元多项式本身由一维多项式组成。每个一维多项式为不同的连续概率分布类型提供最佳基础。每个基的最优性来自其相对于连续分布的概率密度函数的正交性。
例子
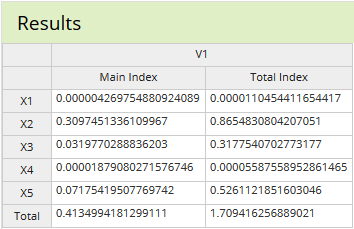
在此示例中,使用基于 gPCE 的方法对由五个输入变量和一个输出变量组成的数据集执行敏感性分析。输入变量概率分布是根据其预期的不确定性进行预测的,这用于生成实验的稀疏网格设计。然后使用实验设计对系统进行评估,并将结果输出用于 gPCE 分析。表中总结了主效应和总效应。SmartUQ 甚至可以在稀疏网格数据集有缺失值时执行敏感性分析。
不确定性的传播计算系统输入中的不确定性对系统输出的影响。在量化对系统输出的信心时,此信息至关重要。
考虑到输入的预期变化,不确定性的传播有助于确定系统输出是否满足要求。这使得估计结果的概率、成本有效地确定所需的容差以及在故障发生之前预测更多故障成为可能。
SmartUQ 在易于使用的工具中提供高级随机数学,并具有两种计算不确定性传播的方法,基于仿真器和广义多项式混沌扩展 (gPCE)。
不确定性的传播基于与每个系统输入相关的不确定性来计算系统输出中的不确定性。所有模型、预测和测量都有与之相关的不确定性。各种输入的不确定性,例如初始条件、环境参数和测量误差,都可能以意想不到的方式影响模拟或测试的结果。
在确定设计或决策是否成功时,了解模拟和测试结果中不确定性的来源和规模至关重要。因此,在为高后果决策提供坚实基础时,不确定性的传播是一个重要工具。
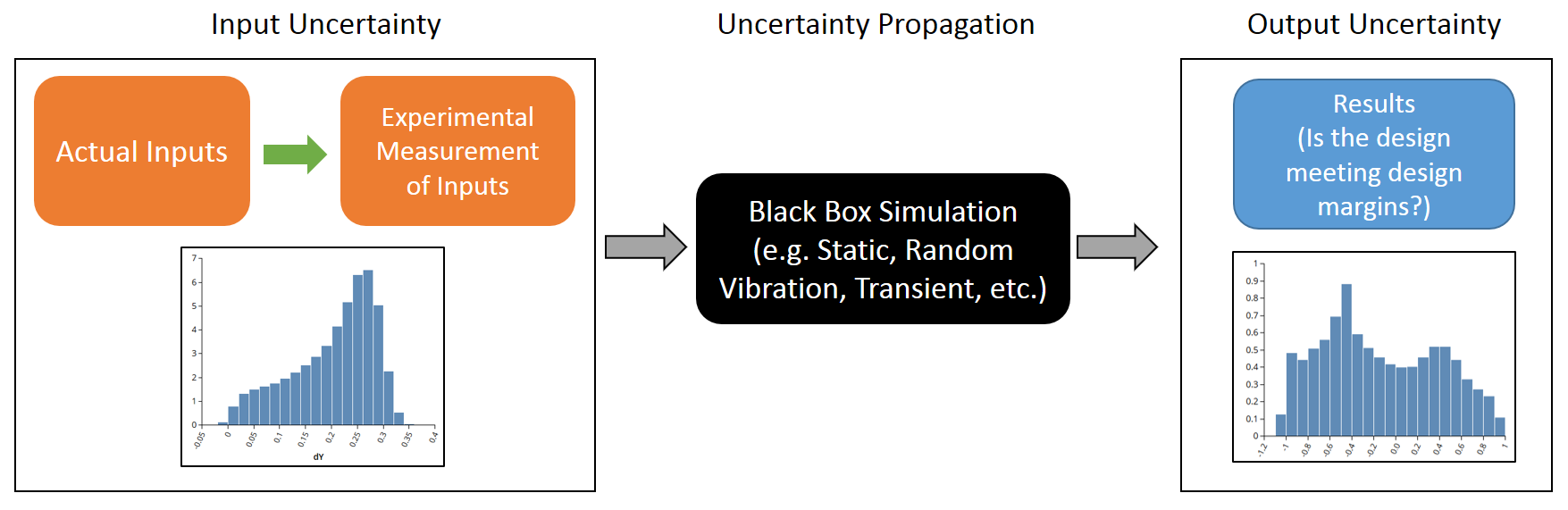 图 1:不确定性信息流的传播 信息流在典型的不确定性计算中模拟传播。
图 1:不确定性信息流的传播 信息流在典型的不确定性计算中模拟传播。从历史上看,不确定性结果的传播是通过使用大型 DOE(如蒙特卡罗方法)运行系统输入并观察输出行为来计算的。不幸的是,对于大规模和高维问题,所需的 DOE 尺寸非常大,计算不确定性传播变得非常昂贵和缓慢。
基于仿真器的不确定性计算传播已成为一种流行的解决方案,因为与采样密集型方法相比速度有所提高。但是模拟器的使用通常仅限于较小的问题,因为使用大型复杂数据集构建模拟器在计算上很困难。
现在,使用 SmartUQ 的突破性技术,基于仿真器的大规模问题的不确定性传播只需点击几下即可。
我们直观的工具使您可以快速获取先前构建的仿真器,并使用概率分布或现有输入参数集(例如来自预期系统操作条件或记录测试的参数集)定义不确定的输入。
例子
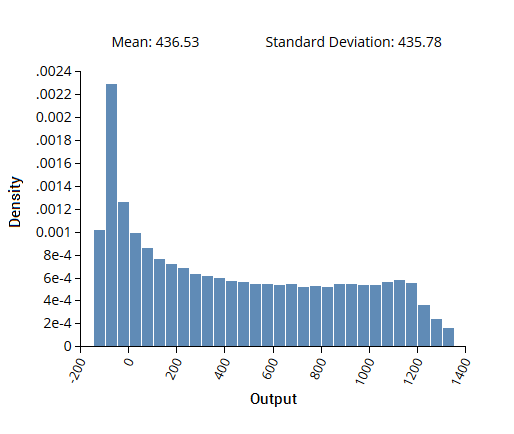 图 2:基于仿真器的不确定性传播
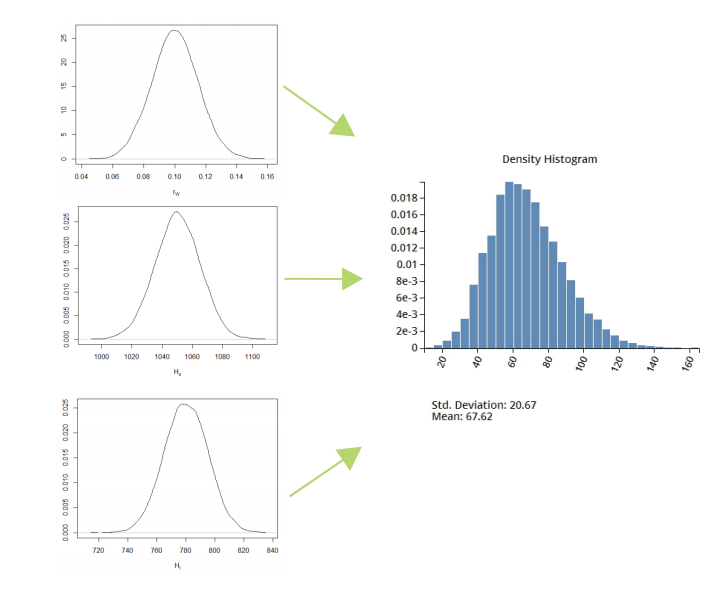
图 2:基于仿真器的不确定性传播在此示例中,构建了一个仿真器并用于计算由三个输入变量和一个输出变量组成的仿真数据集的不确定性传播。输入变量根据其预期的不确定性分配概率分布。给定分配的输入分布,输出的计算密度分布如上所示。
SmartUQ 具有易于使用的广义多项式混沌扩展 (gPCE) 工具。gPCE 是一种应用数学技术,用于使用一系列多元多项式来估计系统的行为。使用稀疏网格 DOE 对要评估的系统进行采样,然后使用 gPCE 来近似随机输出与其每个随机输入之间的函数关联。然后使用该近似值来计算不确定性传播和灵敏度分析结果。gPCE 在稀疏网格 DOE 所需的点数少和结果计算速度方面都是一种高效技术。
对于输出,gPCE 可以写成一系列多元多项式。多元多项式本身由一维多项式组成。每个一维多项式为不同的连续概率分布类型提供最佳基础。每个基的最优性来自其相对于连续分布的概率密度函数的正交性。
例子
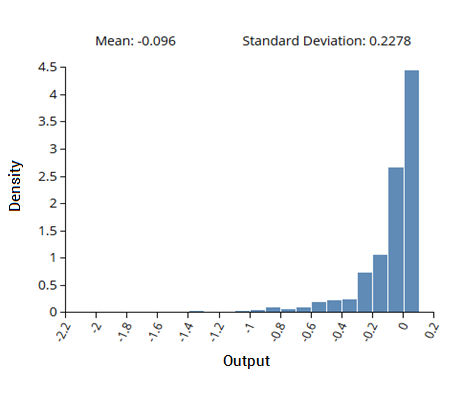 图 3:用于传播不确定性的广义多项式混沌展开
图 3:用于传播不确定性的广义多项式混沌展开在此示例中,基于 gPCE 的方法用于计算由五个输入变量和一个输出变量组成的数据集的不确定性传播。输入变量概率分布是根据其预期的不确定性进行预测的,这用于生成稀疏网格 DOE。然后使用 DOE 对系统进行评估,并将结果输出用于 gPCE 分析。在给定输入概率分布的情况下,计算出的输出密度分布如上所示。
统计校准概述 结合使用专有的自适应 DOE 和我们突破性的仿真器,统计优化可以快速评估设计空间并预测有前景的区域。
统计优化适用于低维和高维问题。我们的软件最大限度地减少了为各种问题获得最佳结果所需的模拟运行次数,并且能够处理大量输入和输出类型,包括二进制和离散、多个约束以及具有多个目标的优化。
通过 SmartUQ 中的统计优化,您可以使用基于迭代 DOE 的采样技术来提高对整个设计空间和可能包含最佳点的区域的了解。以并行批次运行采样 DOE,而不是按顺序运行单点,可以充分利用计算资源,并且可以以数百倍的速度提供答案。
作为一个额外的好处,可以通过使用相同的系统评估来寻找优化以及优化结果的分析和 UQ 分析来实现显着的节省。您不仅可以探索设计空间的最优区域,还可以确定最优值对输入参数变化的敏感程度,以及最优点周围的变化是否会导致意外或不良行为,例如违反约束。
统计优化和基于搜索的优化功能(如遗传算法)的组合可用于利用两者的最佳特性。
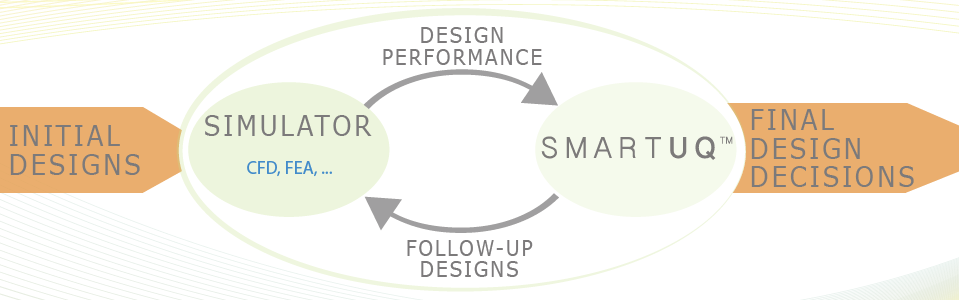 图 1:统计优化流程图
图 1:统计优化流程图不确定性下的优化是在部分或全部输入不确定时优化系统输出的过程。与其进行优化以找到一组条件的最佳点,不如关注识别在一系列条件下表现良好的点,并围绕这些最佳值分析系统的行为。
如果不研究最佳设计点周围的行为,就很难避免不稳定的最佳状态,因为最终产品的正常变化可能会导致不良行为。
例如,在优化喷气发动机的效率时,需要考虑材料特性、制造尺寸和实际系统运行条件的不确定性。由于实际发动机的不确定性,它可能会在最佳设计点附近但不是在最佳设计点运行。如果目标是在确保发动机不违反污染排放要求的同时优化最高效率,则有必要了解发动机在最佳设计点附近的行为。这有助于确保,对于设计输入中的已知不确定性,发动机效率始终是可接受的,并且永远不会违反污染要求。
基于仿真器的优化是将优化算法应用于仿真器,利用极快的预测速度彻底覆盖设计空间。依靠我们的高质量仿真技术,SmartUQ 有一个内置的优化库,能够处理具有混合连续和分类输入、多目标以及输入和输出约束的高维问题。
借助 SmartUQ,使用仿真器作为复杂系统的轻量级替代品可以显着减少系统评估次数和获得解决方案所需的时钟时间。
与统计优化一样,一旦构建了仿真器,它们就会为理解底层系统行为和最佳点的属性提供额外的价值。
逆向分析使用系统模型和相应的噪声数据来表征系统的未知随机参数。未知参数在模拟和物理数据分析中很常见,这种技术在量化参数值、不确定性和分布方面发挥着重要作用。下图显示了典型逆分析问题的处理流程。
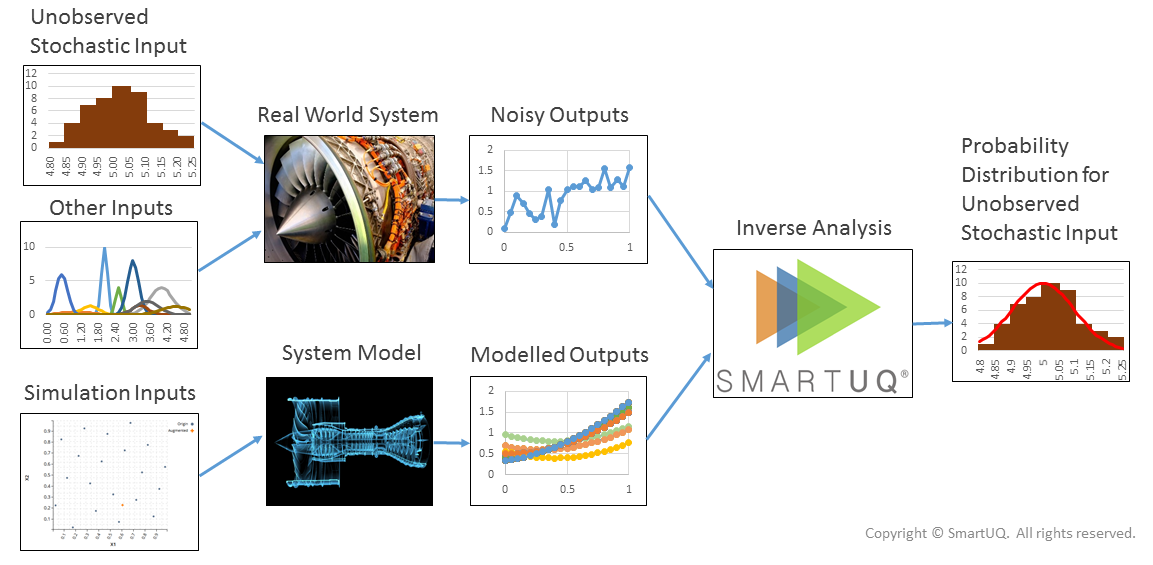 图1:逆分析信息流示意图
图1:逆分析信息流示意图通过逆分析分析的未知系统属性通常包括未知的控制方程、形状、大小、边界和初始值、材料属性、通量和力。逆分析问题的格式不正确,因为无法保证唯一的解决方案,并且确定性方法通常无法产生适用的结果。噪声数据、数值计算错误和建模不准确使使用确定性方法的困难更加严重。概率方法和不确定性量化为分析这些问题提供了更可靠的方法。
了解不确定输入的分布是有效实施不确定性量化和随机设计过程的第一步。这些分布还可用于许多其他目的,例如确定零件合规性和实际系统性能。
在航空航天工业中,典型的逆分析应用包括确定理想形状以匹配特定压力分布、估计复杂系统的结构参数以及使用扫描数据识别零件中的不规则性。
在地面车辆制造中,典型的逆分析应用包括满足概率目标的系统设计、根据机器性能数据确定未知操作和环境条件,以及根据噪声操作数据识别组件属性。
SmartUQ 的逆分析估计功能利用系统模型和相应的噪声物理测试数据来估计系统未知随机输入的概率分布特征。这些随机输入通常很难观察到物理值、没有直接物理对应关系的模型属性或未知边界和初始条件。
例如,在飞机或车辆中使用的实际部件的材料特性,例如杨氏模量,可能由于制造变化而无法准确知道。输入分布估计功能采用相关的组件响应数据,例如力和应变测量,并估计物理部件中材料属性的分布特征。
SmartUQ 可以处理逆向分析问题,而仿真运行次数少得多,而时间和计算成本只是其一小部分。这种效率和速度允许将逆分析方法应用于更多数据集,从而产生更完整的分析和不确定性量化。
公司优势
超过12年行业服务经验为您的产品研发设计保驾护航
35个
多项发明专利,35个软件著作权。
60家
十二年服务于顶尖研发企业
138个
覆盖全国城市
999+
口碑好评
安怀信正向设计研发港
扫一扫,关注我们
微信小程序安怀信
搜一搜,关注我们
© Copyright 2014-2025 北京安怀信科技股份有限公司 网站声明 版权所有 京ICP备12040064号-1


